

算法导论
1. 算法在计算中的作用
如何选择最佳的排序算法?
需要考虑多种因素:
- 待排序的数据项数
- 这些数据项已排好序的程度
- 对数据项取值的可能限制
- 打算采用的存储设备的类型(内存、磁盘、磁带等)
算法重要吗?
- 算法是当代计算机中用到的大部分技术的核心
- 是否拥有扎实的算法知识和技术基础,是区分真正熟练的程序员与新手的一项重要特征
2. 算法入门
在本章介绍了插入排序以及合并排序。
2.1. 插入排序
[方法]:循环不变式帮助理解算法的正确性,它有三个性质:
- 初始化 在循环的第一轮迭代开始之前,应该是正确的。
- 保持 下一次迭代开始之前,也应该保持正确
- 终止 当循环结束时,终止归纳。
这里使用了循环不变式来证明插入排序的正确性。 插入排序的伪代码如下所示:
INSERTION-SORT(A)
for j <- 2 to length[A] // 这里length是对象A的一个属性/方法,用于求出数组A的长度
do key <- A[j]
// Insert A[j] into the sorted sequence A[1..j-1]
i <- j-1
while i > 0 and A[i] > key
do A[i+1] <- A[i]
i <- i - 1
A[i+1] <- key
可以在这里查看插入排序的动画:图解算法
伪代码中的约定:
<-:赋值
A[i]:数组A中的第i个元素,注意不是第i+1个元素。
2.2. 算法分析
针对一个算法所需要的资源进行预测,需要建立有关实现技术的模型。 常常将一个程序的运行时间表示为其输入的函数。 本书一般考察的是最坏情况。
2.3. 算法设计
增量法: 在排好子数组A[1..j-1]后,将元素A[j]插入,形成排好序的子数组A[1..j]。
2.3.1. 分治法
三个步骤;
- 分解
- 解决
- 合并
举例子:合并排序
// 假设子数组A[p..q]和A[q+1..r]已经排好序,并将他们合并成一个已排好序的子数组代替当前子数组A[p..r]
merge(A, p, q, r) {
n1 = q - p + 1
n2 = r - q
create arrays L[1..n1+1] and R[1..n2+1]
for i = 1 to n1
do L[i] = A[p+i-1]
for j = 1 to n2
do R[j] = A[q+j]
L[n1+1] = ∞
R[n2+1] = ∞
i = 1
j = 1
for k = p to r
do if (L[i] ≤ R[j])
then A[k] = L[i]
i = i + 1
else A[k] = R[j]
j = j + 1
}
合并排序的完整伪代码程序:
merge-sort(A, p, r) {
if (p < r)
then q = (p+r)/2
merge-sort(A, p, q)
merge-sort(A, q+1, r)
merge(A, p, q, r)
}
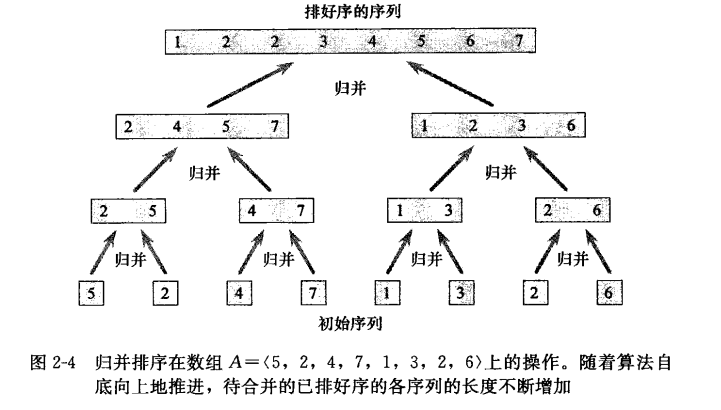
合并过程由图2-4所示,分而治之最终合并。
时间复杂度分析:
下面展示了计算时间复杂度的过程。
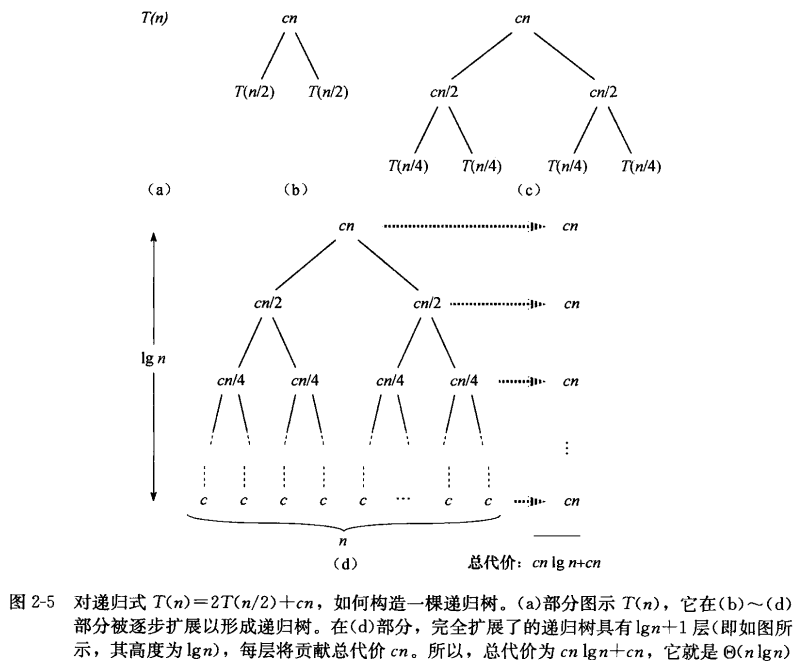
推导思路:
算法本身的递归式 -> 最坏运行时间T(n)的递归式 -> 数学分析得到T(n)=O(nlgn)
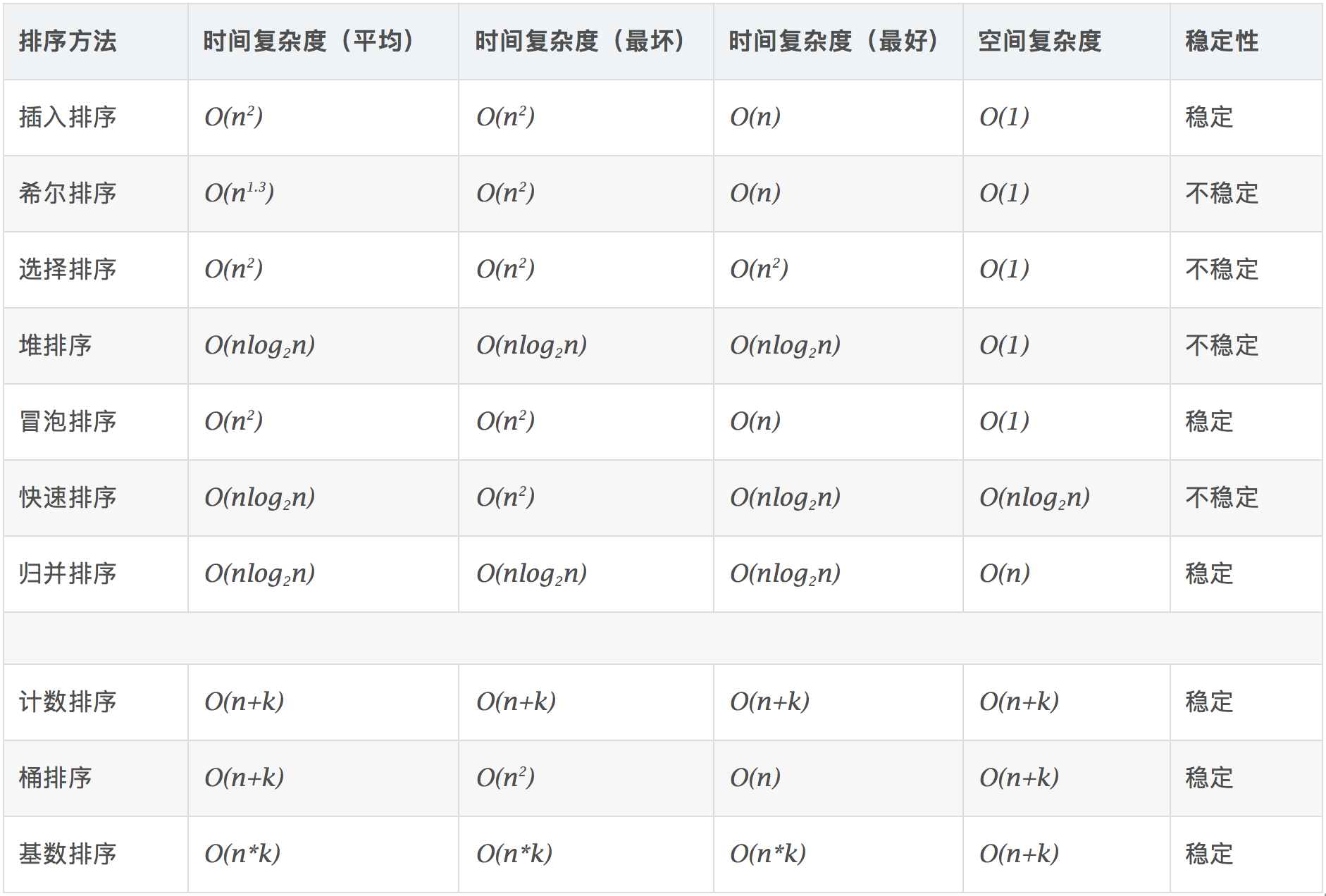
不同的排序方式之间的时间复杂度分析:
3. 函数
为了更好的计算算法的运行时间,介绍一些记号和数学符号。
4. 递归式
通过第3章介绍的数学方法来计算递归式的运行时间。