PostgreSQL 数据库内核分析-c7
-
date_range 01/01/2021 00:00
点击量:次infosortPostgreSQLlabelPostgreSQL数据库事务书籍
第7章 事务处理与并发控制
7.1 事务系统简介
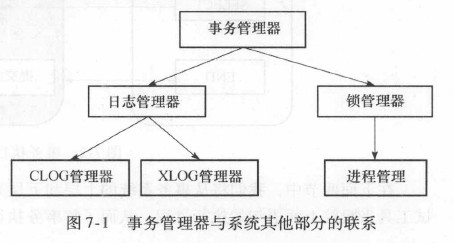
- 事务管理器是事务系统的中枢, 它的实现是一个有限状态自动机, 通过接受外部系统的命令或者信号, 并根据当前事务所处的状态, 决定事务的下一步执行过程。
- 事务执行的写阶段需要由各种锁保证事务的隔离级别
- 日志管理器用来记录事务执行的状态以及数据的变化过程, 包括事务提交日志(CLOG)和事务日志(XLOG)。
BEGIN;
SELECT * FROM test;
END;
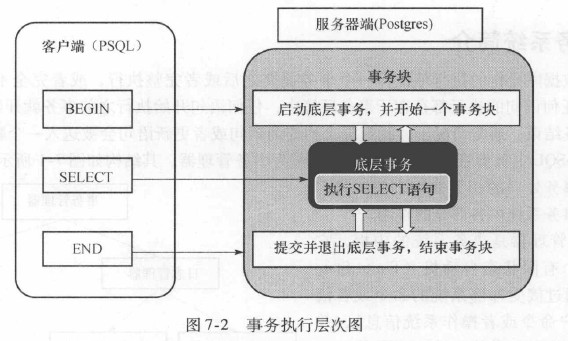
7.2 事务系统的上层
概念定义:
事务: PostgreSQL中的事务实际上是数据库理论中的命令概念。
“事务” : 数据库理论中谈到的事务概念。
PostgreSQL执行一条SQL语句前会调用StartTransactionCommand函数, 执行结束时调用CommitTransactionCommand。如果命令执行失败,调用AbortCurrentTransaction函数。
事务系统上层的入口函数, 不处理具体事务
- StartTransactionCommand
- CommitTransactionCommand
- AbortCurrentTransaction
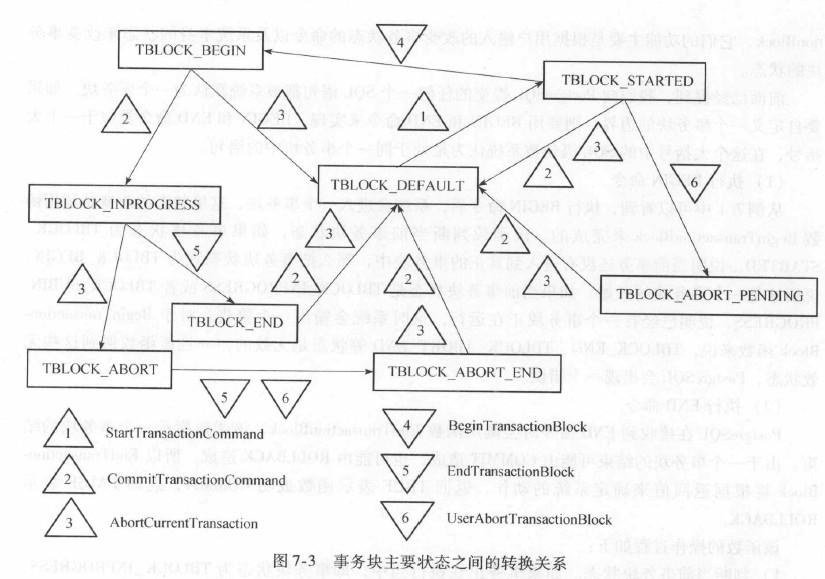
7.2.1 事务块状态
整个事务系统的状态, 反映了当前用户输入命令的变化过程和事务底层的执行状态的变化。 其数据结构是一个枚举类型。
typedef enum TBlockState
{
/* not-in-transaction-block states */
TBLOCK_DEFAULT, /* idle */
TBLOCK_STARTED, /* running single-query transaction */
/* transaction block states */
TBLOCK_BEGIN, /* starting transaction block */
TBLOCK_INPROGRESS, /* live transaction */
TBLOCK_END, /* COMMIT received */
TBLOCK_ABORT, /* failed xact, awaiting ROLLBACK */
TBLOCK_ABORT_END, /* failed xact, ROLLBACK received */
TBLOCK_ABORT_PENDING, /* live xact, ROLLBACK received */
TBLOCK_PREPARE, /* live xact, PREPARE received */
/* subtransaction states */
TBLOCK_SUBBEGIN, /* starting a subtransaction */
TBLOCK_SUBINPROGRESS, /* live subtransaction */
TBLOCK_SUBRELEASE, /* RELEASE received */
TBLOCK_SUBCOMMIT, /* COMMIT received while TBLOCK_SUBINPROGRESS */
TBLOCK_SUBABORT, /* failed subxact, awaiting ROLLBACK */
TBLOCK_SUBABORT_END, /* failed subxact, ROLLBACK received */
TBLOCK_SUBABORT_PENDING, /* live subxact, ROLLBACK received */
TBLOCK_SUBRESTART, /* live subxact, ROLLBACK TO received */
TBLOCK_SUBABORT_RESTART /* failed subxact, ROLLBACK TO received */
} TBlockState;
7.2.2 事务块操作
7.2.2.1 事务块基本操作
- StartTransactionCommand 判断当前事务块的状态进入不同的底层事务执行函数中,是进入事务处理模块的入口函数
- CommitTransactionCommand 在每条SQL语句执行后调用
- AbortCurrentTransaction 当系统遇到错误时,返回到调用点并执行该函数。
7.2.2.2 事务块状态的改变
通过接受外部系统的命令或者信号, 并根据当前事务所处的状态, 决定事务块的下一步状态。
事务块状态改变函数:
- BeginTransactionBlock
执行
BEGIN命令 - EndTransactionBlock
执行
END命令 - UserAbortTransactionBlock
执行
ROLLBACK命令
一些概念:
BEGIN和END命令类似一个大括号,在这个大括号的SQL语句被系统认为是处于同一个事务块中的语句。- 事务之间存在嵌套关系,如子事务和顶层事务之间的关系,通过
TransactionStateData::nestingLevel来表示
事务块状态机:
7.3 事务系统的底层
7.3.1 事务状态
低层次的事务状态通过TransState来表示
typedef enum TransState
{
TRANS_DEFAULT, /* idle */
TRANS_START, /* transaction starting */
TRANS_INPROGRESS, /* inside a valid transaction */
TRANS_COMMIT, /* commit in progress */
TRANS_ABORT, /* abort in progress */
TRANS_PREPARE /* prepare in progress */
} TransState;
事务处理过程中存储事务状态相关数据的数据结构是TransactionStateData
typedef struct TransactionStateData
{
TransactionId transactionId; /* my XID, or Invalid if none */
SubTransactionId subTransactionId; /* my subxact ID */
char *name; /* savepoint name, if any */
int savepointLevel; /* savepoint level */
TransState state; /* low-level state */
TBlockState blockState; /* high-level state */
int nestingLevel; /* transaction nesting depth */
int gucNestLevel; /* GUC context nesting depth */
MemoryContext curTransactionContext; /* my xact-lifetime context */
ResourceOwner curTransactionOwner; /* my query resources */
TransactionId *childXids; /* subcommitted child XIDs, in XID order */
int nChildXids; /* # of subcommitted child XIDs */
int maxChildXids; /* allocated size of childXids[] */
Oid prevUser; /* previous CurrentUserId setting */
int prevSecContext; /* previous SecurityRestrictionContext */
bool prevXactReadOnly; /* entry-time xact r/o state */
bool startedInRecovery; /* did we start in recovery? */
struct TransactionStateData *parent; /* back link to parent */
} TransactionStateData;
- nestingLevel
每通过
PushTransaction函数开启一个子事务,该子事务的nestingLevel将在父事务的基础上加1。 - curTransactionOwner
指向
ResourceOwner的指针, 用于记录当前事务占有的资源。
7.3.2 事务操作函数
执行实际的事务操作。
7.3.2.1 启动事务
- StartTransaction
7.3.2.2 提交事务
- CommitTransaction
7.3.2.3 退出事务
在系统遇到错误时调用
- AbortTransaction
7.3.2.4 清理事务
释放事务所占用的内存资源
- CleanupTransaction
7.3.3 简单查询事务执行过程实例

处理的事务:
BEGIN;
SELECT * FROM test;
END;
相关过程的关键函数:
- BEGIN
- StartTransactionCommand
- StartTransaction
- ProcessUtility
- BeginTransactionBlock
- CommitTransactionCommand
- SELECT
- StartTransactionCommand
- ProcessQuery
- EndTransactionBlock
- END
- StartTransactionCommand
- ProcessUtility
- CommitTransactionBlock
- CommitTransactionCommand
- CommitTransaction
7.4 事务保存点和子事务
保存点的作用主要是实现事务的回滚, 即从当前子事务回滚到该事务链中的某个祖先事务。
BEGIN Transaction S;
insert into table1 values(1);
SAVEPOINT P1;
insert into table1 values(2);
SAVEPOINT P2;
insert into table1 values(3);
ROLLBACK TO savepoint P1;
COMMIT;
语句的执行结果是在表table1中插入数据1;
7.4.1 保存点实现原理
typedef struct TransactionStateData
{
struct TransactionStateData *parent; /* back link to parent */
} TransactionStateData;
parent指向本事务的父事务,层次结构如下:

子事务的层次描述用一个栈链实现, 栈顶元素拥有一个指向其父事务的指针。 当启动一个新的子事务时, 系统调用PushTransaction函数将该子事务的TransactionState结构变量压入栈中。
相关的几个切换父子事务关系的函数, 修改栈的状态并更新CurrentTransactionState:
- PushTransaction
- PopTransaction
7.4.2 子事务
主要作用: 实现保存点, 增强事务操作的灵活性。
子事务相关函数:
- StartSubTransaction
- CommitSubTransaction
- CleanupSubTransaction
- AbortSubTransaction
7.5 两阶段提交
实现分布式事务处理的关键是两阶段提交协议。
7.5.1 预提交阶段
在分布式事务处理中存在一个协调者的角色, 负责协调和远端数据库之间的事务同步。

我的小问题: 在事务的恢复操作过程中,
Redo和Undo有什么区别?
7.5.2 全局提交阶段
本地数据库根据协调者的消息, 对本地事务进行COMMIT或者ABORT操作。
7.6 PostgreSQL的并发控制
利用多版本并发控制来维护数据的一致性。 同时有表和行级别的锁定机制、会话锁机制。
4个事务隔离级别:
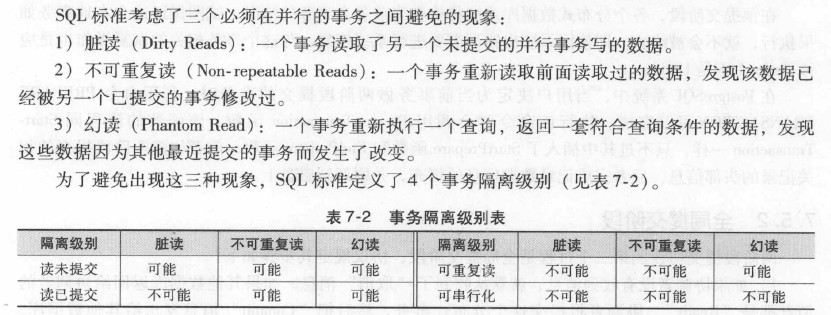
事务隔离级别所涉及的最小实体是元组, 所以对元组的操作需要实施访问控制,他们是通过锁操作以及MVCC相关的操作来实现的.
-
读已提交 一个
SELECT查询只能看到查询开始之前提交的数据,而永远无法看到未提交的数据或者是在查询执行时其他并行的事务提交所做的改变。 -
可串行化 提供最严格的事务隔离。
举例说明以上两种级别的差异:
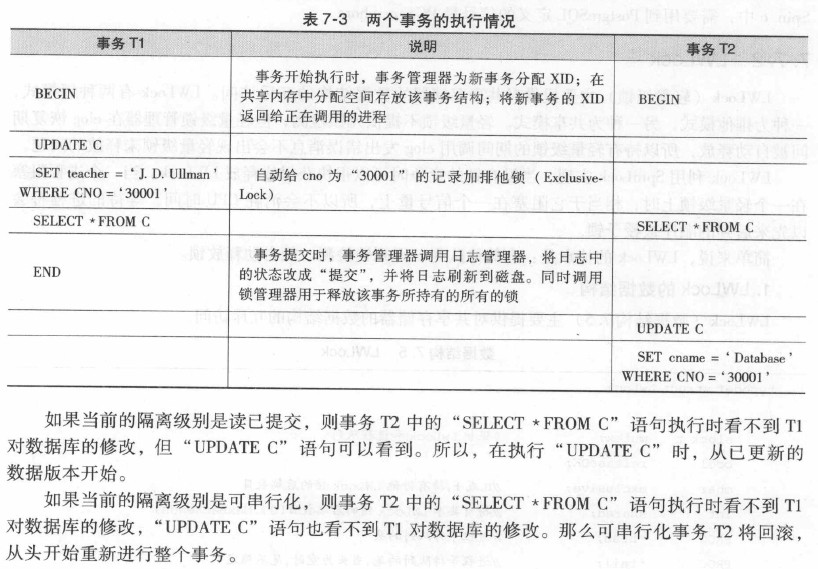
7.7 PostgreSQL中的三种锁
7.7.1 SpinLock
机器相关的实现s_lock.c :使用TAS指令集实现
机器不相关的实现Spin.c
7.7.2 LWLock(轻量级锁)
主要提供对共享存储器的数据结构的互斥访问。
通过SpinLock实现
特点: 有等待队列、 无死锁检测、 能自动释放锁。
typedef struct LWLock
{
slock_t mutex; /* Protects LWLock and queue of PGPROCs */
bool releaseOK; /* T if ok to release waiters */
char exclusive; /* # of exclusive holders (0 or 1) */
int shared; /* # of shared holders (0..MaxBackends) */
PGPROC *head; /* head of list of waiting PGPROCs */
PGPROC *tail; /* tail of list of waiting PGPROCs */
/* tail is undefined when head is NULL */
} LWLock;
使用SpinLock对mutex进行加解锁即可实现一个对LWLock的互斥访问。
系统在共享内存中用一个全局数组LWLockArray来管理所有的LWLock。
7.7.2 LWLock的主要操作
- LWLock的空间分配
- LWLock的创建
- LWLock的分配
LWLockAssign
- LWLock的锁的获取
LWLockAcquireLWLockConditionalAcquire
- LWLock的锁的释放
LWLockRelease
7.7.3 RegularLock
通过LWLock实现
特点: 有等待队列、 有死锁检测、 能自动释放锁。
RegularLock支持的锁模式有8种, 按级别从低到高分别是:
#define NoLock 0
#define AccessShareLock 1 /* SELECT */
#define RowShareLock 2 /* SELECT FOR UPDATE/FOR SHARE */
#define RowExclusiveLock 3 /* INSERT, UPDATE, DELETE */
#define ShareUpdateExclusiveLock 4 /* VACUUM (non-FULL),ANALYZE, CREATE
* INDEX CONCURRENTLY */
#define ShareLock 5 /* CREATE INDEX (WITHOUT CONCURRENTLY) */
#define ShareRowExclusiveLock 6 /* like EXCLUSIVE MODE, but allows ROW
* SHARE */
#define ExclusiveLock 7 /* blocks ROW SHARE/SELECT...FOR
* UPDATE */
#define AccessExclusiveLock 8 /* ALTER TABLE, DROP TABLE, VACUUM
* FULL, and unqualified LOCK TABLE */
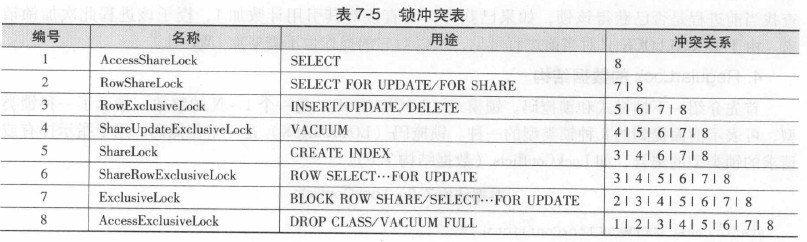
RegularLock的粒度可以是数据库的表、元组、页等, 请求锁的主体既可以是事务, 也可以是跨事务的会话。
RegularLock的主要操作:
- 初始化:
InitLocks - 申请:
LockAcquire - 释放:
LockRelease - 释放本地锁:
RemoveLocalLock - 锁的冲突检测:
LockCheckConflicts
7.8 锁管理机制
7.8.1 表粒度的锁操作
7.8.2 页粒度的锁操作
7.8.3 元组粒度的锁操作
7.8.4 事务粒度的锁操作
7.8.5 一般对象的锁操作
7.9 死锁处理机制
7.9.1 死锁处理相关数据结构
7.9.2 死锁处理相关操作
7.10 多版本并发控制
引子:
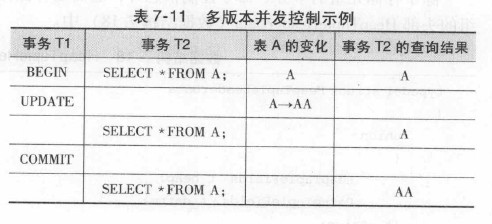
7.10.1 MVCC相关数据结构
更新数据时并非使用新值覆盖旧值, 而是在表中另外开辟一片空间来存放新的元组, 让新值和旧值同时存放在数据库中, 同时设置一些参数让系统识别他们。
元组的描述信息使用数据结构HeapTupleFields(存储元组的事务、命令控制信息),
HeapTupleHeaderData(存储元组的相关控制信息)。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
typedef struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
// 一个新元组被保存在磁盘中的时候, 其`t_ctid`就被初始化为它自己的实际存储位置。
ItemPointerData t_ctid; /* current TID of this or newer tuple */
/* Fields below here must match MinimalTupleData! */
uint16 t_infomask2; /* number of attributes + various flags */
// 当前元组的事务信息
uint16 t_infomask; /* various flag bits, see below */
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
bits8 t_bits[1]; /* bitmap of NULLs -- VARIABLE LENGTH */
/* MORE DATA FOLLOWS AT END OF STRUCT */
} HeapTupleHeaderData;
一个新元组被保存在磁盘中的时候, 其t_ctid就被初始化为它自己的实际存储位置。
一个元组是最新版本的充要条件: 当且仅当它的xmax为空或者它的t_ctid指向它自己。
t_ctid是一个链表结构, 可以通过遍历这个版本链表来找到某个元组的最新版本。
MVCC的基本原理:
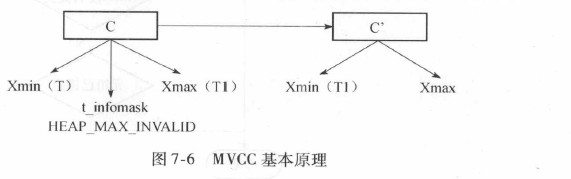
根据C和C'的头信息中的Xmin和Xmax以及t_infomask来判断出C为有效版本, C'为无效版本。
7.10.2 MVCC相关操作
MVCC操作所需要调用的相关函数, 核心功能是用来判断元组的状态, 包括元组的有效性、可见性、可更新性等。
7.10.2.1 判断元组对于自身信息是否有效
// TRUE: 该元组有效
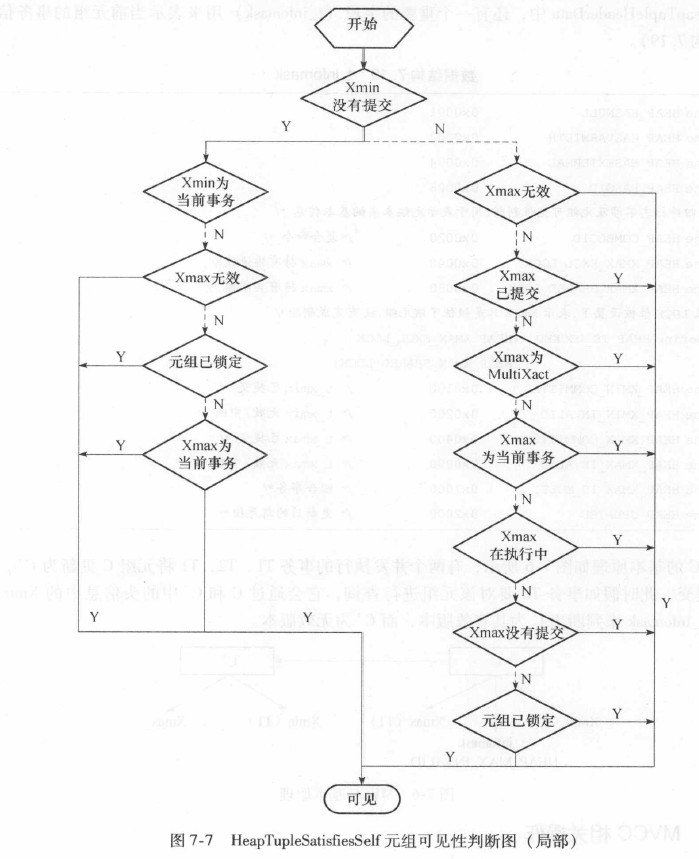
bool HeapTupleSatisfiesSelf(HeapTuple htup, Snapshot snapshot, Buffer buffer)
HeapTupleSatisfiesSelf函数的逻辑:
7.10.2.2 判断元组对当前时刻是否有效
// TRUE: 该元组有效
bool HeapTupleSatisfiesNow(HeapTuple htup, Snapshot snapshot, Buffer buffer);
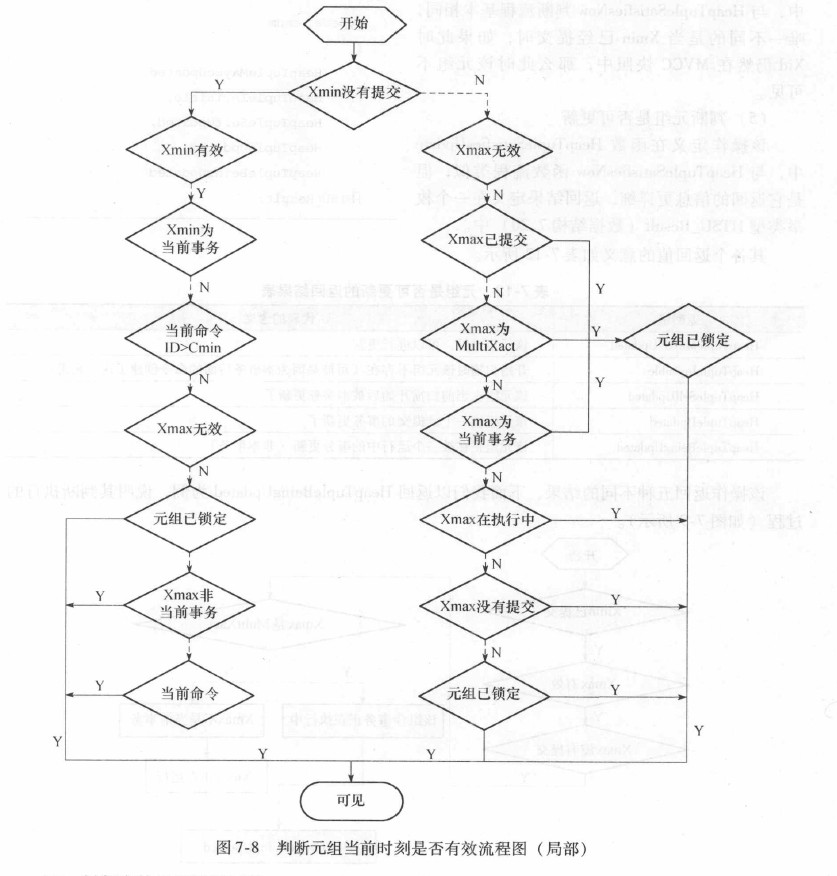
其他判断条件出口为不可见。
7.10.2.3 判断当前元组是否已脏
如果为脏, 则需要立即从磁盘重新读取该元组, 获得其有效版本。
static bool HeapTupleSatisfiesDirty(HeapTuple htup, Snapshot snapshot, Buffer buffer);
7.10.2.4 判断元组对MVCC某一版本是否有效
7.10.2.5 判断元组是否可更新
typedef enum
{
HeapTupleMayBeUpdated,
HeapTupleInvisible,
HeapTupleSelfUpdated,
HeapTupleUpdated,
HeapTupleBeingUpdated
} HTSU_Result;
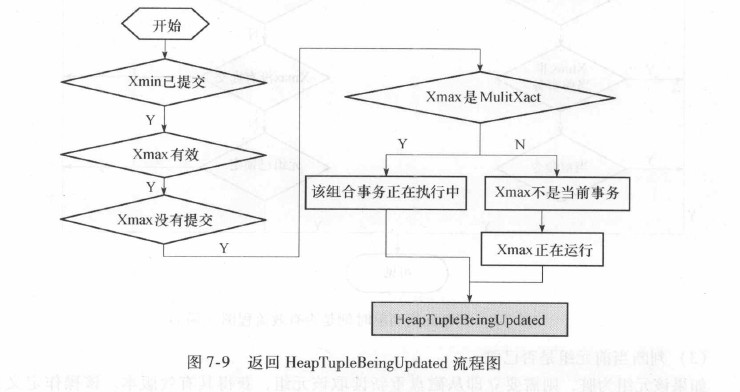
HTSU_Result
HeapTupleSatisfiesUpdate(HeapTupleHeader tuple, CommandId curcid,
Buffer buffer);

HeapTupleSatisfiesUpdate函数返回HeapTupleMayBeUpdated的判断过程, 如下所示:
7.10.3 MVCC与快照
快照Snapshot记录了数据库当前某个时刻的活跃事务列表。
其数据结构如下:
typedef struct SnapshotData
{
// 7.10.2 MVCC相关操作函数
SnapshotSatisfiesFunc satisfies; /* tuple test function */
/*
* The remaining fields are used only for MVCC snapshots, and are normally
* just zeroes in special snapshots. (But xmin and xmax are used
* specially by HeapTupleSatisfiesDirty.)
*
* An MVCC snapshot can never see the effects of XIDs >= xmax. It can see
* the effects of all older XIDs except those listed in the snapshot. xmin
* is stored as an optimization to avoid needing to search the XID arrays
* for most tuples.
*/
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
TransactionId *xip; /* array of xact IDs in progress */
uint32 xcnt; /* # of xact ids in xip[] */
/* note: all ids in xip[] satisfy xmin <= xip[i] < xmax */
int32 subxcnt; /* # of xact ids in subxip[] */
TransactionId *subxip; /* array of subxact IDs in progress */
bool suboverflowed; /* has the subxip array overflowed? */
bool takenDuringRecovery; /* recovery-shaped snapshot? */
bool copied; /* false if it's a static snapshot */
/*
* note: all ids in subxip[] are >= xmin, but we don't bother filtering
* out any that are >= xmax
*/
CommandId curcid; /* in my xact, CID < curcid are visible */
uint32 active_count; /* refcount on ActiveSnapshot stack */
uint32 regd_count; /* refcount on RegisteredSnapshotList */
} SnapshotData;
7.11 日志管理
XLOG : 事务日志, 记录事务对数据更新的过程和事务的最终状态。
CLOG : 事务提交日志, 记录了事务的最终状态, 是XLOG的一种辅助形式。
为了降低写入日志带来的I/O开销, 数据库系统在实现时往往设置了日志缓冲区, 日志缓冲区满了以后以块为单位向磁盘写出。
pg中有四种日志管理器:
XLOG: 事务日志CLOG: 事务提交日志, 使用SLRU缓冲池来实现日志管理SUBTRANS: 子事务日志, 使用SLRU缓冲池来实现日志管理MULTIXACT: 组合事务日志, 使用SLRU缓冲池来实现日志管理
7.11.1 SLRU缓冲池
对CLOG和SUBTRANS日志的物理存储组织方法,每个物理日志文件定义成一个段(32个8KB大小的磁盘页面)。 通过二元组<Segmentno, Pageno>可以定位日志页在哪个段文件以及在该文件中的偏移位置。
7.11.1.1 SLRU缓冲池的并发控制
使用轻量级锁实现对SLRU缓冲池的并发控制。
7.11.1.2 SLRU缓冲池相关数据结构
SlruCtlData提供缓冲池的控制信息。
typedef struct SlruCtlData
{
SlruShared shared;
/*
* This flag tells whether to fsync writes (true for pg_clog and multixact
* stuff, false for pg_subtrans and pg_notify).
*/
bool do_fsync;
/*
* Decide which of two page numbers is "older" for truncation purposes. We
* need to use comparison of TransactionIds here in order to do the right
* thing with wraparound XID arithmetic.
*/
bool (*PagePrecedes) (int, int);
/*
* Dir is set during SimpleLruInit and does not change thereafter. Since
* it's always the same, it doesn't need to be in shared memory.
*/
char Dir[64];
} SlruCtlData;
SlruFlushData记录打开的物理磁盘文件, 当进行刷写操作时, 将对多个文件的更新数据一次性刷写到磁盘。
typedef struct SlruFlushData
{
int num_files; /* # files actually open */
int fd[MAX_FLUSH_BUFFERS]; /* their FD's */
int segno[MAX_FLUSH_BUFFERS]; /* their log seg#s */
} SlruFlushData;
7.11.1.3 SLRU缓冲池的主要操作
- 缓冲池的初始化
- 缓冲池页面的选择
- 页面的初始化
- 缓冲池页面的换入换出
- 缓冲池页面的删除
7.11.2 CLOG日志管理器
CLOG是系统为整个事务管理流程所建立的日志,主要用于记录事务的状态,同时通过SUBTRANS日志记录事务的嵌套关系。
7.11.2.1 相关数据结构
事务的最终状态分成以下四种:
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03
通过一个4元组<Segmentno, Pageno, Byte, Bindex>可定位一条CLOG日志记录。
通过一个事务的事务ID可以获得其日志对应的4元组。
- TransactionIdToPage(xid)
- TransactionIdToPgIndex(xid)
- TransactionIdToByte(xid)
- TransactionIdToBIndex(xid)
CLOG的控制信息如下所示:
/*
* Link to shared-memory data structures for CLOG control
*/
static SlruCtlData ClogCtlData;
#define ClogCtl (&ClogCtlData)
7.11.2.2 CLOG日志管理器主要操作
- 初始化
CLOGShmemInit - 写操作
TransactionIdSetStatusBit - 读操作
TransactionIdGetStatus - CLOG日志页面的初始化
ZeroCLOGPage - CLOG日志的启动
StartupCLOG - CLOG日志的关闭
ShutdownCLOG - CLOG日志的扩展
ExtendCLOG, 为新分配的事务ID创建CLOG日志空间。 - CLOG日志的删除
TruncateCLOG - 创建检查点时CLOG日志的操作
CheckPointCLOG:执行一个CLOG日志检查点,在XLOG执行检查点时被调用。
我的小问题:
CheckPoint是什么?完成什么工作?
CheckPoint是事务日志序列中的一个点, 在该点上所有数据文件都已经被更新为日志中反映的信息,所有数据文件将被刷写到磁盘。
检查点是在事务序列中的点,这种点保证被更新的堆和索引数据文件的所有信息在该检查点之前已被写入。在检查点时刻,所有脏数据页被刷写到磁盘,并且一个特殊的检查点记录将 被写入到日志文件(修改记录之前已经被刷写到WAL文件)。在崩溃时,崩溃恢复过程检查 最新的检查点记录用来决定从日志中的哪一点(称为重做记录)开始REDO操作。在这一点 之前对数据文件所做的任何修改都已经被保证位于磁盘之上。因此,完成一个检查点后位于 包含重做记录的日志段之前的日志段就不再需要了
我的小问题:
WAL文件的物理组织形式是什么? 它是相对于日志文件有什么性能上的优势?
磁盘盘片的写入处理可能因为电力失效在任何时候失败, 这意味有些扇区写入了数据,而有些没有。为了避免这样的失效,PostgreSQL在修改磁盘上的实际页面之前, 周期地把整个页面的映像写入永久WAL存储。
Checkpoints are points in the sequence of transactions at which it is guaranteed that the heap and index data files have been updated with all information written before the checkpoint.
At checkpoint time, all dirty data pages are flushed to disk and a special checkpoint record is written to the log file.
(The changes were previously flushed to the WAL files.)
In the event of a crash, the crash recovery procedure looks at the latest checkpoint record to determine the point in the log (known as the redo record) from which it should start the REDO operation.
Any changes made to data files before that point are guaranteed to be already on disk. Hence, after a checkpoint, log segments preceding the one containing the redo record are no longer needed and can be recycled or removed. (When WAL archiving is being done, the log segments must be archived before being recycled or removed.)
CheckPoint中的工程折中问题考虑:
CheckPoint的IO活动会对性能产生较大负担, 所以CheckPoint的活动会被有所限制以减少对性能的影响。
降低checkpoint_timeout和/或max_wal_size会导致检查点更频繁地发生。这使得崩溃后恢复更快,因为需要重做的工作更少。但是,我们必须在这一点和增多的刷写脏数据页开销之间做出平衡。
7.11.3 SUBTRANS日志管理器
通过SUBTRANS日志记录事务的嵌套关系, 管理一个缓冲池, 存储每一个事务的父事务ID。
7.11.4 MULTIXACT日志管理器
用来记录组合事务ID的一种日志, 同一个元组相关联的事务ID可能有多个, 为了在加锁的时候统一操作, PostgreSQL将与该元组相关联的多个事务ID组合起来用MULTIXACT代替来管理。
7.11.5 XLOG日志管理器
每个XLOG文件被分为一个个大小为16MB的XLOG段文件来存放。
XLOG文件号和段文件号可以用来唯一地确定这个段文件, 使用一个XLOG文件号和日志记录在该文件内的偏移量可以确定一个日志文件内的一个日志记录。
7.11.5.1 XLOG日志管理器相关数据结构
- 日志页面头部信息
typedef struct XLogPageHeaderData { uint16 xlp_magic; /* magic value for correctness checks */ uint16 xlp_info; /* flag bits, see below */ TimeLineID xlp_tli; /* TimeLineID of first record on page */ XLogRecPtr xlp_pageaddr; /* XLOG address of this page */ } XLogPageHeaderData;
对于一个长的XLOG日志记录, 可能在当前页面中没有足够空间来存储, 系统允许将剩余的数据存储到下一个页面, 即一个XLOG记录分开存储到不同的页面。
/*
* When the XLP_LONG_HEADER flag is set, we store additional fields in the
* page header. (This is ordinarily done just in the first page of an
* XLOG file.) The additional fields serve to identify the file accurately.
*/
typedef struct XLogLongPageHeaderData
{
XLogPageHeaderData std; /* standard header fields */
uint64 xlp_sysid; /* system identifier from pg_control */
uint32 xlp_seg_size; /* just as a cross-check */
uint32 xlp_xlog_blcksz; /* just as a cross-check */
} XLogLongPageHeaderData;
- 日志记录控制信息
XLOG日志记录结构:
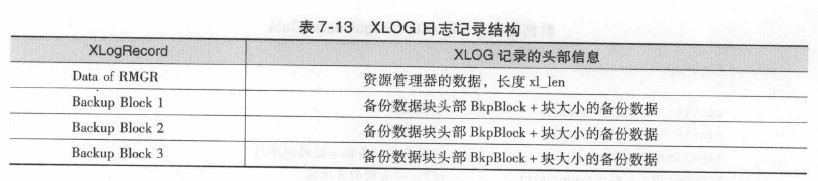
typedef struct XLogRecord
{
pg_crc32 xl_crc; /* CRC for this record */
XLogRecPtr xl_prev; /* ptr to previous record in log */
TransactionId xl_xid; /* xact id */
uint32 xl_tot_len; /* total len of entire record */
uint32 xl_len; /* total len of rmgr data */
uint8 xl_info; /* flag bits, see below */
RmgrId xl_rmid; /* resource manager for this record */
/* Depending on MAXALIGN, there are either 2 or 6 wasted bytes here */
/* ACTUAL LOG DATA FOLLOWS AT END OF STRUCT */
} XLogRecord;
通过xl_rmid和xl_info获悉对源数据做的操作类型, 迅速正确地调用对应的函数。
- 日志记录数据信息
```cpp typedef struct XLogRecData { char data; / start of rmgr data to include / uint32 len; / length of rmgr data to include / Buffer buffer; / buffer associated with data, if any / bool buffer_std; / buffer has standard pd_lower/pd_upper / struct XLogRecData *next; / next struct in chain, or NULL */ } XLogRecData;
/* 备份数据块头部信息 / typedef struct BkpBlock { RelFileNode node; / relation containing block / ForkNumber fork; / fork within the relation / BlockNumber block; / block number / uint16 hole_offset; / number of bytes before “hole” / uint16 hole_length; / number of bytes in “hole” */
/* ACTUAL BLOCK DATA FOLLOWS AT END OF STRUCT */ } BkpBlock;
/* 指向XLOG中某个位置的指针 / typedef struct XLogRecPtr { uint32 xlogid; / log file #, 0 based / uint32 xrecoff; / byte offset of location in log file */ } XLogRecPtr;
- **XLOG控制结构**
```cpp
typedef struct XLogCtlData
{
/* Protected by WALInsertLock: */
XLogCtlInsert Insert;
/* Protected by info_lck: */
XLogwrtRqst LogwrtRqst; /* 在该值之前的日志记录都已经刷新到磁盘 */
uint32 ckptXidEpoch; /* nextXID & epoch of latest checkpoint */
TransactionId ckptXid;
XLogRecPtr asyncXactLSN; /* LSN of newest async commit/abort */
uint32 lastRemovedLog; /* latest removed/recycled XLOG segment */
uint32 lastRemovedSeg;
……………………
slock_t info_lck; /* locks shared variables shown above */
} XLogCtlData;
- XLOG日志的checkpoint策略
typedef struct CheckPoint { XLogRecPtr redo; /* next RecPtr available when we began to * create CheckPoint (i.e. REDO start point) */ TimeLineID ThisTimeLineID; /* current TLI */ bool fullPageWrites; /* current full_page_writes */ uint32 nextXidEpoch; /* higher-order bits of nextXid */ TransactionId nextXid; /* next free XID */ Oid nextOid; /* next free OID */ MultiXactId nextMulti; /* next free MultiXactId */ MultiXactOffset nextMultiOffset; /* next free MultiXact offset */ TransactionId oldestXid; /* cluster-wide minimum datfrozenxid */ Oid oldestXidDB; /* database with minimum datfrozenxid */ pg_time_t time; /* time stamp of checkpoint */ /* * Oldest XID still running. This is only needed to initialize hot standby * mode from an online checkpoint, so we only bother calculating this for * online checkpoints and only when wal_level is hot_standby. Otherwise * it's set to InvalidTransactionId. */ TransactionId oldestActiveXid; } CheckPoint;
检查点策略如下: 1) 标记当前日志文件中可用的日志记录点,该过程不允许其他事务写日志。 2) 刷新所有修改过的数据缓冲区, 该过程允许其他事务写日志。 3) 插入检查点日志记录, 并把日志记录冲刷到日志文件中。
7.11.5.2 XLOG日志管理器的主要操作
参考: 深入理解缓冲区(十三)
- 日志的启动
BootStrapCLOG - 日志文件的创建
InstallXLogFileSegment - 日志的插入
XLogInsert: 事务执行插入、删除、更新、提交、终止或者回滚命令时需要调用该函数。 - 日志文件的归档
XLogWrite: 将日志写到磁盘日志文件中, 调用本函数时需要持有WALWriteLock(日志写锁) - 日志文件的刷新
XLogFlush: 确保到达给定位置的所有XLOG数据都被刷写回磁盘。
我的小问题:
XLogWrite和XLogFlush有什么区别?
实际上XLogWrite会调用XLogFlush。
- 日志的打开操作
XLogFileInit - 日志文件的拷贝
XLogFileCopy - 日志备份块的恢复
RestoreBackupBlock - 日志记录的读取
ReadRecord - 创建
checkpointCreateCheckPoint - 创建
RestartPoint系统在恢复过程中创建的日志恢复检查点。
7.11.5.3 日志恢复策略
系统崩溃重启后调用StartXlog入口函数, 该函数扫描global/pg_control读取系统的控制信息, 然后扫描XLOG日志目录的结构读取到最新的日志checkpoint记录, 判断系统是否处于非正常状态下, 若系统处于非正常状态, 则触发恢复机制进行恢复。
以下三种情况需要执行恢复操作:
- 日志文件中扫描到
bakeup_label文件 - 根据
ControlFile记录的最新checkpoint读取不到记录日志 - 根据
ControlFile记录的最新checkpoint与通过该记录找到的检查点日志中的Redo位置不一致。
恢复操作的具体步骤:

7.11.6 日志管理器总结
CLOG是系统为整个事务管理流程所建立的日志,主要用于记录事务的状态,同时通过SUBTRANS日志记录事务的嵌套关系。
XLOG是数据库日志的主体,记录数据库中所有数据操作的变化过程, XLOG日志管理器模块提供了日志操作的API供其他模块调用。
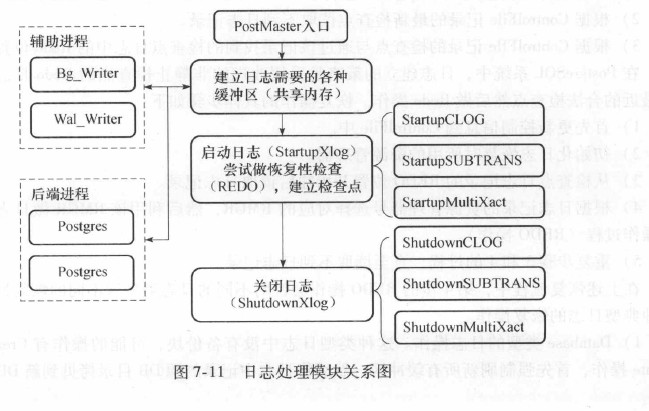
日志处理模块关系图: