

perfbook-c5
5 Counting
5.1 Why Isn’t Concurrent Counting Trivial?
- 并发计数不使用有原子操作的情况下会出错
- 并发计数在使用原子操作的情况下,随着核数的增多,自增效率越来越低,如下图所示:

原因如下图所示:

在做原子操作的时候需要多个CPU的协同确认。
5.2 Statistical Counters
5.2.1 Design
设计思想如下图所示:

根据加法结合律和加法交化律,在各个CPU各自加,在读的时候将各个CPU的值加起来。
5.2.2 Array-Based Implementation
代码路径:count\count_stat.c
DEFINE_PER_THREAD(unsigned long, counter);
static __inline__ void inc_count(void)
{
unsigned long *p_counter = &__get_thread_var(counter);
WRITE_ONCE(*p_counter, *p_counter + 1);
}
static __inline__ unsigned long read_count(void)
{
int t;
unsigned long sum = 0;
for_each_thread(t)
sum += READ_ONCE(per_thread(counter, t));
return sum;
}
对update侧友好,对expense侧不友好。
在读的时候需要访问所有的处理器一遍,在这个过程中,实际上各个处理器的进程内变量counter还可以继续增加,所以算出来的值实际上是不精确的。
5.2.3 Eventually Consistent Implementation
代码路径:count\count_stat_eventual.c
5.2.2节介绍的计数算法要求保证返回的值在read_count()执行前一刻的计数值和read_count()执行完毕时的计数值之间。5.2.3提供了一种弱一些的保证:不调用inc_count()时,调用read_count()最终会返回正确的值。
/* 定义每线程变量 */
DEFINE_PER_THREAD(unsigned long, counter);
struct {
__typeof__(unsigned long) v __attribute__((__aligned__(CACHE_LINE_SIZE)));
} __per_thread_counter[NR_THREADS];
/* 定义全局counter */
unsigned long global_count;
count_init
eventual
while(stopflag < 3) {
unsigned long sum = 0;
for_each_thread(t) sum += READ_ONCE(per_thread(counter, t));
WRITE_ONCE(global_count, sum);
poll(NULL, 0, 1);
if (READ_ONCE(stopflag)) {
smp_mb();
WRITE_ONCE(stopflag, stopflag + 1);
}
}
count_cleanup
stopflag = 1
static __inline__ unsigned long read_count(void)
{
return READ_ONCE(global_count);
}
若count_cleanup中置位stopflag,eventual最后计算3次后退出。
否则,eventual一直在计算sum并写入global_count中。
对比5.2.2中的实现,相当于引入了一个变量global_count来做缓冲,每次读的时候只读global_count。
5.2.4 Per-Thread-Variable-Based Implementation
代码路径:count\count_end.c
/* 使用gcc提供的一个用于每线程存储的_thread存储类 */
unsigned long __thread counter = 0; //\lnlbl{var:b}
/* 定义数组存放各个线程变量的地址 */
unsigned long *counterp[NR_THREADS] = { NULL };
/* 定义全局counter */
unsigned long finalcount = 0;
/* 全局自旋锁 */
DEFINE_SPINLOCK(final_mutex);
/* 自增线程内的计数变量counter */
static __inline__ void inc_count(void)
{
WRITE_ONCE(counter, counter + 1);
}
static __inline__ unsigned long read_count(void)
{
int t;
unsigned long sum;
spin_lock(&final_mutex);
sum = finalcount;
for_each_thread(t)
if (counterp[t] != NULL)
sum += READ_ONCE(*counterp[t]);
spin_unlock(&final_mutex);
return sum;
}
/* 在自旋锁的保护下初始化全局数组,实际上这个自旋锁可以去掉,
* 因为这里访问的位置对各个线程来说是原子独占的,
* 这里只是为了安全起见保留了。 */
void count_register_thread(unsigned long *p)
{
int idx = smp_thread_id();
spin_lock(&final_mutex);
counterp[idx] = &counter;
spin_unlock(&final_mutex);
}
/* 在自旋锁的保护下做全局counter的累加,排除了有进程调用 read_count()同时又有进程调用
* count_unregister_thread()的情况。*/
void count_unregister_thread(int nthreadsexpected)
{
int idx = smp_thread_id();
spin_lock(&final_mutex);
finalcount += counter;
counterp[idx] = NULL;
spin_unlock(&final_mutex);
}
小问题5.23:为什么我们需要用像互斥锁这种重量级的手段来保护5.9的read_count()函数中的累加总和操作?
当一个线程退出时,它的每线程变量将会消失。因此,如果我们试图在线程退出后,访问它的每线程变量,将得到一个段错误。这个锁保护求和操作和线程退出以防止出现这种情况。
count_register_thread()函数,每个线程在访问自己的计数前都要调用它。
count_unregister_thread()函数,每个之前调用过count_register_thread()函数的线程在退出时都需要调用该函数。
评价:这个方法让更新者的性能几乎和非原子计数一样,并且也能线性地扩展。另一方面,并发的读者竞争一个全局锁,因此性能不佳,扩展能力也很差。但是,这不是统计计数器需要面对的问题,因为统计计数器总是在增加计数,很少读取计数。
搞明白问题的范围很重要。
小问题5.25:很好,但是Linux内核在读取每CPU计数的总和时没有用锁保护。为什么用户态的代码需要这么做?
一个规避办法是确保在所有线程结束以前,每一个线程都被延迟,如代码D.2所示。
5.3 Approximate Limit Counters
5.3.1 Design
每个线程都拥有一份每线程变量counter,但同时每个线程也持有一份每线程的最大值countermax。
举个例子,假如某个线程的counter和countermax现在都等于10,那么我们会执行如下操作。
1.获取全局锁。
2.给globalcount增加5。
3.当前线程的counter减少5,以抵消全局的增加。
4.释放全局锁。
5.增加当前线程的counter,变成6。
这就提出了一个问题,我们到底有多在意
globalcount和真实计数值的偏差? 其中真实计数值由globalcount和所有每线程变量counter相加得出。
这个问题的答案取决于真实计数值和计数上限(这里我们把它命名为globalcountmax)的差值有多大。这两个值的差值越大,countermax就越不容易超过globalcountmax的上限。这就代表着任何一个线程的countermax变量可以根据当前的差值计算取值。当离上限还比较远时,可以给每线程变量countermax赋值一个比较大的数,这样对性能和扩展性比较有好处。当靠近上限时,可以给这些countermax赋值一个较小的数,这样可以降低超过统计上限globalcountmax的风险。
关于这个设计有如下问题: 差值如何获取,以怎样的频率获取?在获取这个差值的时候是需要真实计数值的,这个过程需要做一个多线程的
read_count操作,如果这个过程比较频繁,如1ms一次,那么这个设计就变成了5.2.3。
从作者的实现中可以看到:在估计countermax时使用的数据结构是全局数据结构globalcount和globalreserve,而不是线程变量counter。所以不存在上述的问题。
countermax = globalcountmax - globalcount - globalreserve;
countermax /= num_online_threads();
数据结构如下所示:

unsigned long __thread counter = 0;
unsigned long __thread countermax = 0;
unsigned long globalcountmax = 10000;
unsigned long globalcount = 0;
unsigned long globalreserve = 0;
unsigned long *counterp[NR_THREADS] = { NULL };
DEFINE_SPINLOCK(gblcnt_mutex);
每线程变量counter和countermax各自对应线程的本地计数和计数上限。
globalcountmax变量代表合计计数的上限。
globalcount变量是全局计数。
globalcount和每个线程的counter之和就是真实计数值。
globalreserve变量是所有每线程变量countermax的和。
5.3.2 Simple Limit Counter Implementation
代码路径:count\count_lim.c
数据结构图如下所示:

关键算法如下所示:
add_count
/* fast path:本线程资源充足,直接count += dalta
* 如果线程资源有余,直接分配
* 下面的判断为什么不写成 if(count + data <= countermax)
* 因为这种判断有整型溢出的隐患
*/
if (countermax - counter >= delta) {
WRITE_ONCE(counter, counter + delta)
return 1;
}
/* slow path:此时线程内资源不够用了 */
spin_lock(&gblcnt_mutex);
globalize_count();
/* 清除线程本地变量,根据需要调整全局变量,这就简化了全局处理过程。 */
globalcount += counter;
counter = 0;
globalreserve -= countermax;
countermax = 0;
if (globalcountmax -
globalcount - globalreserve < delta)
spin_unlock(&gblcnt_mutex);
return 0;
}
globalcount += delta;
balance_count();
/* 动态调整当前线程的资源阈值,并且将counter设置成新阈值的一半
* 好处:
* (1)允许线程0使用快速路径来减少及增加计数
* (2)如果全部线程都单调递增直到上限,则可以减少不准确程度。
*/
countermax = globalcountmax -
globalcount - globalreserve;
countermax /= num_online_threads()
globalreserve += countermax;
counter = countermax / 2;
if (counter > globalcount)
counter = globalcount;
globalcount -= counter;
spin_unlock(&gblcnt_mutex);
return 1;
sub_count
/* 基本同`add_count` */
5.3.3 Simple Limit Counter Discussion
当合计值接近0时,简单上限计数运行得相当快,只在add_count()和sub_count()的快速路径中的比较和判断时存在一些开销。但是,每线程变量countermax的使用表明add_count()即使在计数的合计值离globalcountmax很远时也可能失败。同样,sub_count()在计数合计值远远大于0时也可能失败。
在许多情况下,这都是不可接受的。即使globalcountmax只不过是一个近似的上限,一般也有一个近似度的容忍限度。一种限制近似度的方法是对每线程变量countermax的值强加一个上限。这个任务将在5.3.4节完成。
5.3.4 Approximate Limit Counter Implementation
代码路径:count\count_lim_app.c
在更新数据结构的时候添加一个上限MAX_COUNTERMAX的判断
static void balance_count(void)
{
countermax = globalcountmax -
globalcount - globalreserve;
countermax /= num_online_threads();
if (countermax > MAX_COUNTERMAX)
countermax = MAX_COUNTERMAX;
globalreserve += countermax;
counter = countermax / 2;
if (counter > globalcount)
counter = globalcount;
globalcount -= counter;
}
5.3.5 Approximate Limit Counter Discussion
- 极大地减小了在前一个版本中出现的上限不准确程度
- 任何给定大小的
MAX_COUNTERMAX将导致一部分访问无法进入快速路径,这部分访问的数目取决于工作负荷。
5.4 Exact Limit Counters
使用原子操作保证精确性
5.4.1 Atomic Limit Counter Implementation:
代码路径:count\count_lim_atomic.c
- 数据结构
atomic_t __thread counterandmax = ATOMIC_INIT(0); unsigned long globalcountmax = 1 << 25; unsigned long globalcount = 0; unsigned long globalreserve = 0; atomic_t *counterp[NR_THREADS] = { NULL }; DEFINE_SPINLOCK(gblcnt_mutex); #define CM_BITS (sizeof(atomic_t) * 4) #define MAX_COUNTERMAX ((1 << CM_BITS) - 1) - 核心逻辑
int add_count(unsigned long delta) { int c; int cm; int old; int new; /* CAS操作,因为counterandmax可能被多线程并发访问(其他线程做flush_local_count操作时) */ do { split_counterandmax(&counterandmax, &old, &c, &cm); if (delta > MAX_COUNTERMAX || c + delta > cm) goto slowpath; new = merge_counterandmax(c + delta, cm); } while (atomic_cmpxchg(&counterandmax, old, new) != old); return 1; slowpath: spin_lock(&gblcnt_mutex); globalize_count(); // 使用原子接口来对数据结构清零:atomic_set(&counterandmax, old); if (globalcountmax - globalcount - globalreserve < delta) { flush_local_count(); // 清空每个线程的counterandmax数据结构 // 将其merge到全局数据结构`globalcount`和`globalreserve` /* 回收其他线程资源之后再次判断,这个方案的核心所在,这里是它更精确的地方。 */ if (globalcountmax - globalcount - globalreserve < delta) { spin_unlock(&gblcnt_mutex); return 0; } } globalcount += delta; balance_count(); spin_unlock(&gblcnt_mutex); return 1; }
小问题5.36:为什么一定要将线程的
coutner和countermax变量作为一个整体counterandmax同时改变?分别改变它们不行吗?
原子地将countermax和counter作为单独的变量进行更新是可行的,但很显然需要非常小心。也是很可能这样做会使快速路径变慢。
小问题5.40:图5.18第11行那个丑陋的
goto slowpath;是干什么用的?你难道没听说break语句吗?
使用break替换goto语句将需要使用一个标志,以确保在第15行是否需要返回,而这并不是在快速路径上所应当干的事情。分支判断会减慢fastpath的速度。
小问题5.43:当图5.20中第27行的flush_local_count()在清零counterandmax变量时,是什么阻止了atomic_add()或者atomic_sub()的快速路径对counterandmax变量的干扰?
答案:什么都没有。考虑以下三种情况。
int add_count(unsigned long delta)
{
int c;
int cm;
int old;
int new;
/* CAS操作,因为counterandmax被多线程并发访问 */
do {
split_counterandmax(&counterandmax, &old, &c, &cm);
if (delta > MAX_COUNTERMAX || c + delta > cm)
goto slowpath;
new = merge_counterandmax(c + delta, cm);
} while (atomic_cmpxchg(&counterandmax,
old, new) != old);
return 1;
……
}
static void flush_local_count(void)
{
zero = merge_counterandmax(0, 0);
for_each_thread(t)
if (counterp[t] != NULL) {
old = atomic_xchg(counterp[t], zero
split_counterandmax_int(old, &c, &cm
globalcount += c;
globalreserve -= cm;
}
……
}
1.如果flush_local_count()的atomic_xchg()在split_counterandmax()之前执行,那么快速路径将看到计数器和counterandmax为0,因此转向慢速路径。
2.如果flush_local_count()的atomic_xchg()在split_counterandmax()之后执行,但是在快速路径的atomic_cmpxchg()之前执行,那么atomic_cmpxchg()将失败,导致快速路径重新运行,这将退化为第1种情况。
3.如果flush_local_count()的atomic_xchg()在split_counterandmax()之后执行,快速路径在flush_local_count()清空线程counterandmax变量前,它将成功运行。
不论哪一种情况,竞争条件将被正确解决。
5.4.2 Atomic Limit Counter Discussion
快速路径上原子操作的开销,让快速路径明显变慢了。
可以通过使用信号处理函数从其他线程窃取计数来改善这一点。
小问题5.45:但是信号处理函数可能会在运行时迁移到其他CPU上执行。难道这种情况就不需要原子操作和内存屏障来保证线程和中断线程的信号处理函数之间通信的可靠性了吗?
答案:不需要。如果信号处理过程被迁移到其他CPU,那么被中断的线程也会被迁移。
5.4.3 Signal-Theft Limit Counter Design

IDLE->REQ:若本线程的theftp被其他线程置成了THEFT_REQ,则说明其他线程的本地计数资源不够用了,请求刷新当前本地计数去支援。
5.4.4 Signal-Theft Limit Counter Implementation
代码路径:count\count_lim_sig.c
数据结构:
int __thread theft = THEFT_IDLE;
int __thread counting = 0;
unsigned long __thread counter = 0;
unsigned long __thread countermax = 0;
unsigned long globalcountmax = 10000;
unsigned long globalcount = 0;
unsigned long globalreserve = 0;
/* 每个线程的允许远程访问的counter变量 */
unsigned long *counterp[NR_THREADS] = { NULL };
/* 每个线程的允许远程访问的countermax变量 */
unsigned long *countermaxp[NR_THREADS] = { NULL };
/* 每个线程的允许远程访问的theft变量 */
int *theftp[NR_THREADS] = { NULL };
DEFINE_SPINLOCK(gblcnt_mutex);
#define MAX_COUNTERMAX 100
信号量通信过程:
count_init
sa.sa_handler = flush_local_count_sig
count_init()设置flush_local_count_sig()为SIGUSR1的信号处理函数,让flush_local_count()中的pthread_kill()可以调用flush_local_count_sig()。
add_count
/* fastpath */
counting = 1;
if (theft == THEFT_IDLE | THEFT_REQ && countermax-counter >= delta) count += delta;
counting = 0;
if (theft == THEFT_ACK) theft = THEFT_READY;
/* slow path */
/* when the combination of the local thread’s count and the g`lobal count cannot accommodate the request*/
flush_local_count
/* 发请求刷新所有线程的本地计数 */
if (*countermaxp[t] == 0) *theftp[t] = THEFT_READY);
WRITE_ONCE(*theftp[t], THEFT_REQ);
pthread_kill(tid, SIGUSR1);
// 信号接收侧进程收到信号之后
flush_local_count_sig
if (theft != THEFT_REQ)
/* the signal handler is not permitted to change the state. */
return;
theft = THEFT_ACK;
if (!counting) theft = THEFT_READY;
/* 循环等待每个线程达到READY状态,然后窃取线程的计数 */
更新全局数据结构
*theftp[t] = THEFT_IDLE;
5.4.5 Signal-Theft Limit Counter Discussion
对于使用信号量的算法来说,更新端的性能提升是以读取端的高昂开销为代价的,POSIX信号不是没有开销的。 原子操作的性能随着不同的计算机体系的不同会有所差异,如果考虑最终的性能,你需要在实际部署应用程序的系统上测试这两种手段。
5.5 Applying Specialized Parallel Counters
对于IO操作可以考虑如下模型:
- 执行
IO操作read_lock(&mylock); if (removing) { read_unlock(&mylock); cancel_io(); } else { add_count(1); read_unlock(&mylock); do_io(); sub_count(1); } - 移除
IO设备write_lock(&mylock); removing = 1; sub_count(mybias); write_unlock(&mylock); while (read_count() != 0) { poll(NULL, 0, 1); } remove_device();
5.6 Parallel Counting Discussion
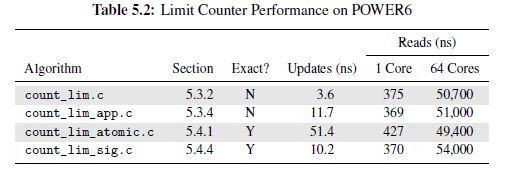
5.6.1 Parallel Counting Performance

5.6.2 Parallel Counting Specializations
只需要简单地铺一块木板,就是一座让人跨过小溪的桥。但你不能用一块木板横跨哥伦比亚河数千米宽的出海口,也不能用于承载卡车的桥。简而言之,桥的设计必须随着跨度和负载而改变,并且,软件也要能适应硬件或者工作负荷的变化,能够自动进行最好。
5.6.3 Parallel Counting Lessons
1.分割能够提升性能和可扩展性。
2.部分分割,也就是只分割主要情况的代码路径,性能也很出色。
3.部分分割可以应用在代码上(5.2节的统计计数器只分割了写操作,没有分割读操作),但是也可以应用在时间上(5.3节和5.4节的上限计数器在离上限较远时运行很快,离上限较按时运行变慢)。
4.读取端的代码路径应该保持只读,内存伪共享严重降低性能和扩展性,就像在表5.1的count_end.c中一样。
伪共享:在同一块缓存线中存放多个互相独立且被多个CPU访问的变量。当某个CPU改变了其中一个变量的值时,迫使其他CPU的本地高速缓存中对应的相同缓存线无效化。这种工程实践会显著地限制并行系统的可扩展性。
5.经过审慎思考后的延迟处理能够提升性能和可扩展性,见5.2.3节。
6.并行性能和可扩展性通常是跷跷板的两端,到达某种程度后,对代码的优化反而会降低另一方的表现。表5.1中的count_stat.c和count_end_rcu.c展现了这一点。
7.对性能和可扩展性的不同需求,以及其他很多因素,会影响算法、数据结构的设计。图5.3展现了这一点,原子增长对于双CPU的系统来说完全可以接受,但对8核系统来说就完全不合适。
提高并行编程性能的3大主要方法:
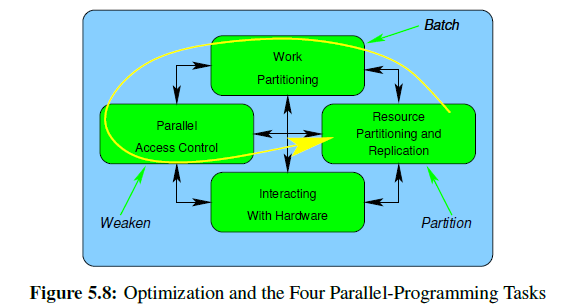
针对并行编程的4个主要部分,可还是如下方法来优化。
- Batch
- Weaken
- Partition
- Special-purpose hardware